NEOM: Unlocking the Future of Sustainable Liv
I. Introduction NEOM is a $500 billion, 26,500 square ...

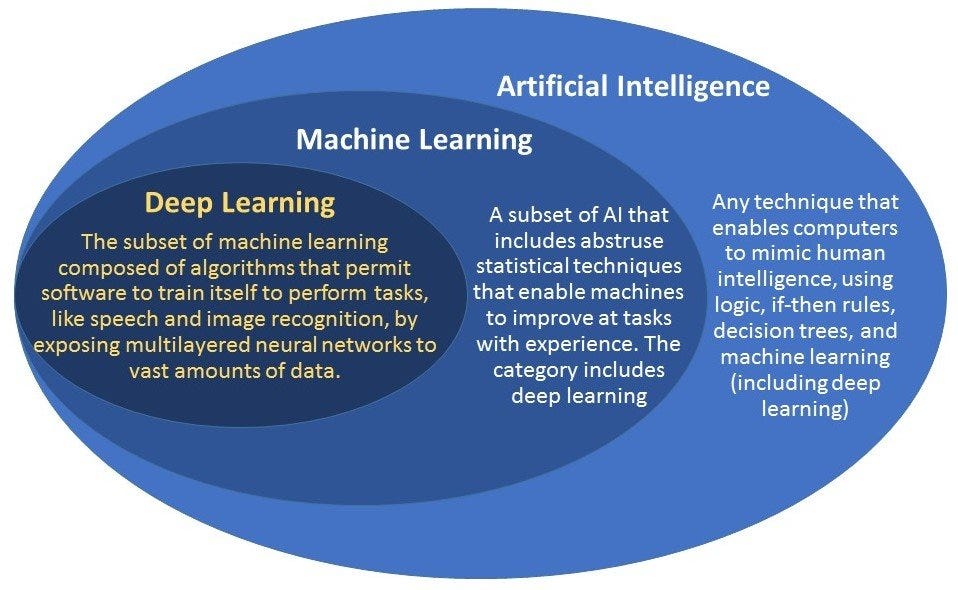
Machine learning is a rapidly growing field of artificial intelligence that has the potential to revolutionize the way we interact with technology. It is a form of artificial intelligence in which computer systems can learn, adapt, and make decisions based on data, instead of relying on predetermined programming or manual intervention. It is different from traditional programming, in which humans are responsible for all aspects of how a system behaves.
Machine learning algorithms provide machines with the ability to learn from vast amounts of data without the need for explicit programming. It is based on the premise that given enough data, computers can be programmed to recognize patterns, make predictions, and take actions without any human intervention. For example, machine learning algorithms can be used to improve search engine results, to automate medical diagnosis, and to make recommendations for online shoppers.
Machine learning algorithms are generally divided into two main categories: supervised and unsupervised learning. Supervised learning algorithms are fed data that is labeled and classified so that they can apply rules or patterns to the data and make predictions. Unsupervised learning algorithms, on the other hand, can detect relationships and patterns in unlabeled data.
In addition to supervised and unsupervised learning, there are also other types of machine learning algorithms such as reinforcement learning, which uses rewards and punishments to encourage a program to act in a certain way. Furthermore, deep learning algorithms can be used to process large amounts of data quickly and accurately.
In conclusion, machine learning is an exciting field of artificial intelligence that has the potential to revolutionize how we interact with technology. By using algorithms to process large amounts of data quickly and accurately, machine learning can help us better understand the world around us. With its ability to adapt and improve over time, machine learning has limitless possibilities for our future.
Machine learning (ML) is an artificial intelligence (AI) technique that enables machines to learn from data, without being specifically programmed. Through machine learning algorithms, computers are able to identify patterns, classify data, and make decisions. The algorithms enable machines to make predictions about future outcomes based on past data.
At its core, ML is the process of using algorithms to parse data, learn from it, and then make a prediction or decision about new data. It builds on previous work in artificial intelligence, and uses techniques such as artificial neural networks (ANNs), deep learning (DL), genetic algorithms (GA), decision trees, support vector machines (SVMs), etc. It involves handing over the problem-solving responsibility to a computer instead of manually programming its behavior.
With machine learning, computers can be taught how to carry out tasks without explicit instructions. By receiving feedback on their performance, machines adjust their actions and continuously improve. This automation allows for faster and more accurate results than manual programming alone. It can be used for a variety of applications such as predictive analytics, fraud detection, autonomous vehicles, natural language processing (NLP), computer vision, and robotics.
Essentially, ML is not just a technology but a scientific discipline that is developing at a rapid pace. As companies increasingly rely on data and AI, ML will continue to play a significant role in how technology advances.
Machine learning is an area of artificial intelligence (AI) concerned with the development and use of algorithms that learn to recognize patterns in data. Machine learning techniques are used for predictive forecasting, anomaly detection, decision making, and data analysis. The goal is to enable computer systems to learn from data, improve their accuracy over time, and make decisions and predictions autonomously.
The basic approach of machine learning is to take data from an input source, analyze it against a set of predetermined criteria, and produce an output such as a decision or a prediction. Machine learning algorithms are often divided into two categories: supervised and unsupervised. Supervised machine learning algorithms use labeled training data to determine the relationship between input variables and output variables; unsupervised machine learning algorithms analyze unlabeled data to discover patterns or associations in the data.
Supervised learning can be either classification or regression. In classification problems, the goal is to categorize instances of data into a set of predefined classes; in regression problems, the goal is to predict a continuous output value based on an input set of features. Examples of supervised learning algorithms are linear regression, logistic regression, support vector machines (SVMs), and artificial neural networks (ANNs).
Unsupervised learning algorithms use unlabeled data to discover patterns or associations in the data. Examples of unsupervised learning algorithms include clustering algorithms, principal component analysis (PCA), hidden Markov models (HMMs), self-organizing maps (SOMs), and deep learning architectures such as deep belief networks (DBNs) and convolutional neural networks (CNNs).
Reinforcement learning is another type of machine learning that has been gaining increased attention in recent years. Reinforcement learning algorithms use feedback loops to improve their accuracy over time. These algorithms use a reward system in order to learn how to achieve an optimal solution. Examples of reinforcement learning algorithms include Markov Decision Processes (MDPs), Q-learning, and Temporal Difference Learning (TD).
There has been a recent surge of interest in machine learning due to advancements in technology and the availability of large datasets. Many organizations have invested in machine learning technology to improve their operations and increase profits. For example, customer segmentation, fraud detection, natural language processing, computer vision, and stock market prediction are all tasks that can be accomplished using machine learning algorithms. Machine learning is also being used for more innovative applications such as autonomous vehicle navigation, robotics, and speech recognition.
Overall, machine learning has revolutionized the way we view computing and artificial intelligence. With continued advances in technology and increased investments from companies and organizations, we can expect to see many more breakthroughs in the field of machine learning in the near future.
The use of machine learning has grown significantly over recent years, with more and more businesses recognizing the potential benefits of using algorithms to gain a competitive edge. Machine learning is a broad discipline that uses data and algorithms to build computer systems that can learn from experience and continually improve their performance. Understanding the fundamentals of machine learning is essential for businesses looking to capitalize on this technology.
At the core of any machine learning system is a set of algorithms that can learn from data and identify patterns in the input. These algorithms are designed to “learn” over time by identifying patterns in data that may not have been previously apparent. In order to do this, the algorithm must be trained with a large amount of data and be able to process it quickly. The type of algorithm used is dependent on the type of problem that is being solved, but most algorithms fall into one of three categories: supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning is the most common form of machine learning because it evaluates and adjusts the algorithm using labeled data sets. Labeled datasets are collections of data where relationships between variables have already been determined. This allows the algorithm to learn more quickly than if it was trying to identify the relationships without guidance. Common examples of supervised learning include image recognition, natural language processing, and facial recognition.
Unsupervised learning takes a different approach to machine learning by analyzing data without prior knowledge or labels. By using unsupervised algorithms, the system can identify patterns in data without any assistance from a human user. Common examples of unsupervised learning include anomaly detection, customer segmentation, and fraud detection.
Reinforcement learning is a type of machine learning that allows an algorithm to modify its behavior based on feedback from its environment. In this type of learning, algorithms are provided with rewards or punishments based on their actions. This type of learning has been used extensively in robotics and autonomous vehicles to allow them to make decisions based on their environment.
Finally, it’s important to understand that all machine learning algorithms require a set of parameters in order to function properly. These parameters determine how the algorithm will process data and make predictions. Tuning these parameters is essential for ensuring that the algorithm produces accurate results in a reasonable amount of time.
In conclusion, understanding the fundamentals of machine learning is essential for businesses looking to make use of this powerful technology. Knowing the types of algorithms available and how to adjust their parameters can help businesses get the most out of their machine learning models and ultimately gain a competitive edge.
Machine learning is an area of artificial intelligence that has grown rapidly in recent years. It is a set of algorithms and techniques used to extract patterns from large datasets, making predictions, and improving the overall performance of machines. Machine learning is used in a variety of industries, from healthcare to retail, and the different types of algorithms vary depending on the task at hand. This article will go over some of the different types of machine learning and their applications.
Supervised Learning: Supervised learning is one of the most common types of machine learning. It is when machines are given labeled data to learn from. That is, each data point comes with a label that tells the machine what category — color, shape, weather — it belongs to. The machine then uses the labeled data to build models that can accurately predict the labels of unseen data. Supervised learning is used to solve regression problems (predicting continuous values) and classification problems (assigning class labels to data points). Common applications of supervised learning include image classification and object detection, language processing, forecasting, and medical diagnosis.
Unsupervised Learning: Unsupervised learning is a type of machine learning that does not require labeled data. Instead, it relies on algorithms to “learn” from unlabeled data. It helps discover hidden structures and relationships in the data that may not be apparent otherwise. Common applications of unsupervised learning include clustering (grouping data points into similar clusters), anomaly detection (identifying outliers in the dataset), and recommendation systems (making product recommendations based on user behavior).
Reinforcement Learning: Reinforcement learning (RL) is a type of machine learning that uses rewards and punishments to learn. It is based on trial-and-error rather than explicit programming. A RL agent starts off with no knowledge about an environment or task and learns through exploration and experience. RL agents gradually become more skilled as they explore and experience more in each environment. Common applications of reinforcement learning include game playing, robotics, autonomous cars, and decision making in complex environments.
Generative Adversarial Networks (GANs): GANs are a type of neural network made up of two parts: a generative network, which creates new data points, and a discriminative network, which evaluates whether the created data points are real or fake. GANs use a game-theoretic approach to learn from unlabeled data. They are very powerful tools for generating novel images or text that appear realistic to humans. GANs are used for applications such as photo editing, style transfer, and text generation.
These are just some of the different types of machine learning algorithms available today. Each type brings something different to the table, but all can be used for applications in a variety of industries. No matter what your goal is, there is sure to be an algorithm out there that can help you achieve it.
Supervised Learning is a type of Machine Learning in which computers are programmed to automate tasks through the use of algorithms and data. This form of learning consists of giving the machine unlabeled examples and a set of labels, which it must use to come up with a model to accurately predict on new data. The model is then tested against a set of labeled data that can be used to evaluate its performance.
The most common method used for supervised learning is known as classification. In this method, the system looks at a dataset of labeled examples, and then predicts the labels for new data accordingly. Classification is used in fields such as fraud detection, medical diagnostics and image analysis.
Another popular supervised learning method is regression. In this case, the system looks at a dataset of labeled examples, and then attempts to predict a numerical value or an output for new data. Regression is commonly used for problems such as predicting stock prices or understanding customer behaviors. It can also be used for forecasting sales and demand, or analyzing customer preferences.
Finally, reinforcement learning is another type of supervised learning that can be used for more complex tasks. In this case, the system interacts with an environment and learns through trial and error. Reinforcement learning has been applied to problems such as robotics and game playing, where the goal is to take an action that maximizes its reward.
Supervised Learning is a powerful tool for many different applications, and it can be used to identify patterns and make predictions with relative accuracy. With the help of supervised learning algorithms and data, it’s possible to automate tasks such as image recognition or fraud detection, making it an invaluable tool for businesses and organizations alike.
Unsupervised learning is an emerging field in the area of machine learning, which offers a potential to reduce human effort required for manual analysis and allows machines to learn more effectively. In this process, machines are provided with a set of raw data with no labels or tags attached to it. The goal is to extract meaningful information from this data with no prior knowledge or assumptions.
Unsupervised learning algorithms use clustering techniques such as K-means, Principal Component Analysis (PCA), Singular Value Decomposition (SVD), Independent Component Analysis (ICA) or Neural Networks (NNs) to recognize the patterns in data. Unlike supervised learning where the input is labelled and the response is predetermined, unsupervised learning does not have any predefined expectations. Instead, it relies on the data itself to provide insight about the underlying structure of the problem or situation.
The data is processed using clustering algorithms which identify groups or clusters of similar objects within the dataset. This information can then be used to make predictions. For example, clustering algorithms can be used for customer segmentation, where businesses can identify customer behavior patterns to offer targeted services or products.
Another application of unsupervised learning is anomaly detection. Anomaly detection algorithms detect abnormal behavior in large amounts of data. This can be used to detect fraudulent activities in financial transactions or detect suspicious behavior in customer databases.
Apart from the above mentioned applications, unsupervised learning can also be used for image processing, natural language processing and text understanding, recommendation systems and much more.
In conclusion, Unsupervised learning can be a powerful tool in the hands of data scientists and machine learning engineers as it eliminates the need for manual labeling and reduces the amount of time invested in finding meaningful insights. It also provides flexibility in creating models that can be further refined and improved with time. With the advances made in Big Data technologies, unsupervised learning is poised to become an essential component of machine learning.
Reinforcement learning is a type of machine learning that enables machines and software agents to learn how to interact with an environment in order to maximize a cumulative reward. This type of learning allows machines and software agents to interact with their environment, explore and make decisions that ultimately lead to the most long-term reward.
In reinforcement learning, an agent learns through trial-and-error interactions with its environment. It is a goal-oriented process that involves continuous experimentation and evaluation. The agent learns by observing its environment, receiving feedback on how the actions it takes affect its environment, and adjusting the behavior accordingly. Through these constant interactions and adjustments, the agent learns which actions yield the most positive outcomes.
Unlike other forms of machine learning, reinforcement learning does not require large amounts of labeled data and is capable of learning with minimal human intervention. Instead, the system is given a set of rewards and punishments for taking certain actions and is then left to explore its environment on its own.
Reinforcement learning has been used in various fields, ranging from robotics to finance. For example, robots have been trained using reinforcement learning to move and grasp objects, play games like chess, and even drive cars autonomously. In finance, reinforcement learning has been used to identify patterns across large datasets in order to make more informed trading decisions.
Overall, reinforcement learning is an exciting area of research and development that has a variety of potential real-world applications. As machine learning continues to develop, we will likely see more uses for reinforcement learning in the future.
Machine learning algorithms are the backbone of any machine learning (ML) system. Without them, there would be no way to identify patterns in data and make useful predictions. Algorithms provide the intelligence of machine learning systems, allowing them to analyze data and develop insights that can be applied to a variety of tasks. In order to understand how ML systems work and how they can be used effectively, it is important to understand the various types of algorithms used for ML.
One of the most common types of algorithms used in machine learning is supervised learning. These algorithms use existing data to “teach” the machine learning system and allow it to make predictions or decisions from new data inputs. Supervised learning algorithms include linear regression, logistic regression, decision trees, support vector machines, and neural networks. Linear regression models use a straight line or curve to predict or explain a dependent variable using one or more independent variables. Logistic regression models use an equation to predict a categorical value based on one or more independent variables. Decision tree models use hierarchical rules to create a model that can classify data points into different categories. Support Vector Machines (SVMs) are used to classify data points by creating decision boundaries that separate the data into different classes. Neural networks consist of multiple layers of neurons between input and output layers which allow them to recognize complex patterns in data.
Unsupervised learning algorithms do not use training data and instead seek to identify patterns in unclassified data sets on their own. Clustering algorithms are one form of unsupervised learning and use statistical techniques to group data points into distinct classes based on their similarities. Examples of clustering algorithms include k-means clustering, hierarchical clustering, and density-based clustering. K-means clustering uses a distance metric such as Euclidean distance to assign data points to clusters with similar characteristics. Hierarchical clustering divides data points into clusters based on their similarity and forms a hierarchical structure or tree-like diagram of clusters. Density-based clustering uses spatial or temporal density to identify clusters within a given dataset.
Reinforcement learning algorithms are self-learning algorithms that allow ML systems to learn from their environment by observing the rewards or consequences from their actions. These types of algorithms are commonly used in robotics, autonomous vehicles, and game playing AI systems. Examples of reinforcement learning algorithms include Q-learning, SARSA (State–Action–Reward–State–Action), and Deep Q-Networks (DQNs). Q-learning is a type of temporal difference learning algorithm that focuses on using feedback from the environment to learn optimal behavior. SARSA is an algorithm for learning a policy for an agent that interacts with an environment using state–action pairs and rewards. DQNs are deep neural networks that work with reinforcement learning algorithms to improve accuracy of decision making.
In conclusion, there are many types of algorithms used in machine learning systems. Supervised learning algorithms use labeled training data to teach the system how to recognize patterns in new data inputs. Unsupervised learning algorithms seek out patterns in unlabeled data sets without training data. Reinforcement learning algorithms use feedback from the system’s environment to learn an optimal behavior policy. Understanding these various types of machine learning algorithms is essential for building effective ML systems that can deliver accurate insights and decisions.
Linear regression is a powerful tool for machine learning and data analysis. It is one of the oldest and most widely used machine learning algorithms and has been around since before computers were even invented. It is a linear approach to modelling the relationship between a dependent variable (Y) and one or more independent variables (X).
The goal of linear regression is to find a best-fit line or curve that predicts the value of the dependent variable for any given value of the independent variable. This line or curve is referred to as the “regression line” and is used to predict the dependent variable. It works by minimizing the sum of squared residuals (or errors) between actual and predicted values.
Linear regression is relatively simple yet powerful machine learning techniques. It can be used to predict a wide range of problems, such as predicting house prices or stock prices, or forecasting future sales or demand. It is also useful in assessing relationships between different variables, identifying trends in data, and detecting outliers.
Linear regression can be implemented using various algorithms available in libraries such as scikit-learn and statsmodels in Python. The most popular algorithm is Ordinary Least Squares (OLS). OLS fits a linear model using the method of least squares and is used to estimate parameters and make predictions based on existing data. Another algorithm that can be used for linear regression is Ridge Regression, which shrinks the regression coefficients towards zero in order to reduce overfitting.
Linear regression can be one of the simplest yet most effective methods for creating machine learning models. Its main advantage is its ability to make predictions from existing data with a minimal amount of effort and know-how. With its relative ease of use, it’s no wonder why linear regression is so popular among data scientists and other professionals alike.
Logistic Regression is a powerful tool for machine learning that can be used to predict the probability of a certain event happening. It is a supervised learning algorithm that is used when the dependent variable is categorical or binary. Logistic regression is an elegant way of representing linear models, and it performs better than linear regression when the data shows a non-linear relationship between the independent and dependent variables.
To understand how logistic regression works, we need to understand the concept of odds ratio. In simple terms, the odds ratio is the probability of an event occurring divided by the probability of that event not occurring. For example, if the odds ratio is 2:1, then there is a two times greater chance of success than failure. In logistic regression, this odds ratio is used to model the probability of an event occurring (positive outcome) given a certain set of independent variables (predictors).
Logistic regression uses maximum likelihood estimation to determine the weights or coefficients associated with each predictor variable. This process ensures that the predicted probability matches the observed frequency of success events as closely as possible. Maximum likelihood estimation also enables us to calculate confidence intervals around our predictions, so we can quantify our level of certainty in the model’s predictive power.
Logistic regression can be used in many different types of machine learning tasks, and it has a wide range of applications in finance, marketing, healthcare, and other industries. It has been used to predict customer churn, credit risk and default rates, disease diagnosis, and success or failure in clinical trials. It can also be used for predicting whether an email is spam or not and for analyzing customer segmentation data.
In conclusion, logistic regression is a powerful tool for machine learning that can be used to predict the probability of an event occurring. It’s fast and reliable, and it allows us to quantify our level of certainty in our predictions. Its wide range of applications makes it one of the most popular algorithms in machine learning today.
Decision Trees are a popular tool in the field of machine learning and are used to predict outcomes by sorting data into classes. In a decision tree, each node represents a test on the attribute, each branch is an outcome of that test, and each leaf node is a class label. This approach is widely used in areas such as business analytics and healthcare.
At its core, a decision tree is a set of if-then rules that allow for split decision-making. Through building the tree, the data is combined in a logical manner so that it can be further explored. A decision tree can be constructed in an iterative way based on an exhaustive exploration of the training data. When a decision tree is used for machine learning, it incorporates a number of techniques that enable it to capture non-linear relationships between data points. Through the use of these techniques, the tree is able to identify and classify complex patterns from data more accurately than linear models can do.
One of the main advantages of using decision trees for machine learning is their interpretability. The rules generated by the decision tree can be easily understood by humans. Decision trees are also relatively easy to build, as they require only a minimal number of decisions. Furthermore, decision trees are able to handle both numerical and categorical data.
It’s important to note that decision trees can be prone to overfitting. This means that they may learn patterns from the data that don’t actually exist and end up memorizing the training dataset instead of generalizing it. To avoid this issue, a technique known as pruning can be used to remove irrelevant branches from the tree and reduce its complexity.
In conclusion, decision trees are a powerful tool for machine learning applications due to their interpretability, ease of construction, and ability to handle both numerical and categorical data. However, it is important to use techniques such as pruning to avoid overfitting.
Support Vector Machines (SVMs) are a powerful tool in machine learning, used to classify and detect patterns in data. SVMs can be used in a wide variety of tasks, such as handwriting recognition, hand gesture recognition, text categorization, image recognition, and more.
At its core, an SVM is a supervised learning algorithm that uses a set of examples to learn how to classify new data points. The goal is to find the best boundary between two classes of data so that it can be used to classify new data points. This boundary is known as the hyperplane.
SVMs use support vectors, a set of points in n-dimensional space from the original training data. These vectors are used to identify the optimal hyperplane that best separates the two classes of data in n-dimensional space. By finding this best hyperplane, SVMs are able to accurately predict the category a new data point belongs to.
SVMs have several advantages over other machine learning algorithms. Firstly, they are capable of dealing with high dimensional spaces – allowing them to capture complex patterns in the data. This makes them especially useful for pattern recognition tasks like image or speech recognition. Additionally, SVMs can handle nonlinear inputs by using the kernel trick. Using different types of kernels allows you to transform the input into a higher dimensional space and create a more accurate classifier. Finally, SVMs are memory efficient since only a subset of the training data is used to create the classification boundary.
Overall, Support Vector Machines are a powerful tool for machine learning and can be used for a variety of applications such as handwriting recognition, text categorization and image recognition. While their use may require some tuning and tweaking of parameters, these parameters can be adjusted to create an effective classifier depending on the problem at hand. Thus, with the right tuning, SVMs can provide accurate predictions even in high dimensional and nonlinear spaces.
Naive Bayes is a powerful and commonly used Machine Learning technique that can be used to solve a variety of problems. It is a probabilistic classification algorithm that works on the assumption of independent predictors. Naive Bayes makes predictions based on probabilities of each predictor being related to the outcome.
The method has been around since the 18th century, but it has found application in modern machine learning as well. This is because Naive Bayes is an easy to understand and implement algorithm that can be successfully applied to a wide range of problems. It is particularly useful when dealing with large datasets, as it provides excellent performance with minimal computational resources.
At its core, the Naive Bayes algorithm uses Bayes’ theorem to calculate posterior probabilities from prior beliefs and data. This is done by estimating the probability of each predictor being associated with the outcome. Naive Bayes then calculates the probability of the entire set of predictors being related to the result. This makes it an ideal choice for situations where there are many potential predictors but limited access to data.
In addition, Naive Bayes is also extremely fast at making predictions. As it only needs to make one pass through the data, it is able to quickly identify patterns and trends in large datasets and make accurate predictions. This makes it perfect for applications such as text categorization, fraud detection and email filtering, where fast response times are important.
Despite its many strengths, the Naive Bayes algorithm has a few weaknesses as well. Because it assumes that all predictors are independent of one another, it can lead to inaccurate results if this assumption is violated. Additionally, it performs poorly when dealing with highly correlated predictors or missing data. Therefore, it is important to use caution when applying Naive Bayes to any machine learning problem.
Overall, Naive Bayes is an excellent choice for many machine learning problems. With its simple yet effective approach, it can provide accurate results with minimal computational resources. Therefore, it should be considered for many applications where there is a need for quick and reliable predictions from large datasets.
F. K-Nearest Neighbors (KNN) is a machine learning algorithm used for classification and regression. The algorithm works by finding the closest “neighbors” in the data and using them to make predictions or classifications. KNN has been used in a variety of applications, including studies of medical diagnosis, consumer rating systems, and crime prediction.
The KNN algorithm begins by finding the distance between the new data point and all other data points. It then finds the K closest data points and uses these points to predict the class or output from the new data point. The number of neighbors used, K, is usually an odd number, as this ensures that ties are avoided when predicting the output or class of the new data point.
While KNN can be used for both classification and regression problems, it is more commonly used for classification. This is because the K nearest neighbors can often provide enough information to accurately classify the new data point. The algorithm works especially well with continuous and categorical variables as well as very large datasets.
KNN also has several advantages over other machine learning algorithms, such as being non-parametric and having no training phase. Furthermore, it requires minimal computing power and can be used for both supervised and unsupervised learning tasks.
Overall, the K-Nearest Neighbors machine learning algorithm is a powerful tool for classification and regression tasks. It works best with continuous and categorical variables as well as large datasets. Furthermore, it has several advantages over other machine learning algorithms, such as being non-parametric and having no training phase. As a result, it has become a popular choice for many machine learning applications.
Machine learning has become increasingly popular in recent years, and its applications are now seen in a wide variety of industries. Machine learning (ML) is a subfield of Artificial Intelligence that enables computers to learn from data and find patterns without explicit programming. ML algorithms can help organizations optimize processes and make decisions based on the data they have collected.
One of the most common applications of machine learning is predictive analytics. Through predictive analytics, you can use historical data to identify patterns and trends in order to forecast future events. This enables organizations to predict potential customer behavior, anticipate market changes, and make better decisions. For example, retail stores can use predictive analytics to forecast demand for products and adjust their inventory accordingly.
Another application of machine learning is computer vision. In this field, ML algorithms are used to identify objects and understand their context. This has enabled AI-based applications to recognize faces, read handwriting, and detect objects in images and videos. This is used in security applications such as facial recognition systems and video surveillance, as well as in healthcare with medical imaging technology.
ML is also used in natural language processing (NLP). NLP employs ML algorithms to process text, such as understanding spoken commands, summarizing long texts, detecting emotions in text, and generating natural-sounding audio responses. This technology is used by virtual assistants such as Siri, Alexa, and Google Assistant. NLP can also be used to analyze customer feedback and reviews on products to gain insights into user experience.
Finally, ML algorithms are also used in recommendation engines. These systems analyze user behavior to recommend items or services that a user may be interested in. This technology is used widely by streaming platforms such as Netflix and streaming music services such as Spotify.
Overall, there are many applications of machine learning across a wide range of industries – from healthcare to retail. With its ability to analyze large amounts of data quickly and accurately, ML will continue to revolutionize the way businesses operate.
Natural language processing (NLP) is an area of artificial intelligence (AI) that deals with the interaction between computers and human languages, in particular how to process and analyze large amounts of natural language data. NLP is a key component of machine learning, which involves the development of algorithms that can take in data from various sources and process them, with the end goal being for the algorithm to be able to predict or make decisions based on that data.
NLP is primarily used to identify patterns in text, and to decipher meaning from those patterns. For example, if an algorithm is presented with a sentence in English, it will first tokenize the sentence to identify each word or phrase. It will then analyze the syntax of the sentence to identify its parts of speech, such as nouns, verbs, and adjectives. Finally, it can assess the meaning of the sentence by recognizing relationships between words and comparing them to a pre-built vocabulary.
NLP is used in many areas, including natural language understanding (NLU) systems, which are used to process spoken and written input, as well as machine translation systems, which are used to help machines understand and translate different languages. NLP is also used in search engines and recommendation systems, where algorithms use NLP techniques to allow users to better search for information.
NLP has many applications in machine learning. For example, it can help machine learning algorithms make better decisions when processing large datasets. It can also be used for sentiment analysis or text classification tasks, where datasets containing opinionated text need to be correctly classified or labelled. Finally, it can be used in recommendation systems, where algorithms can use NLP techniques to better recommend relevant content to users.
In conclusion, NLP is an important component of machine learning and has applications in many different areas of AI. By allowing machines to better understand human language, NLP helps algorithms gain insights from large datasets that would otherwise be difficult for humans to interpret. With continued advancement in this technology, the possibilities for machine learning applications are nearly endless.
Image recognition is a subfield of machine learning which deals with recognizing objects from digital images. It is becoming an increasingly important technology in the fields of artificial intelligence, robotics and computer vision. The ability to accurately detect objects within an image is essential for machines to make sense of their environment and take appropriate action.
Image recognition works by taking an input image and breaking it down into individual components or features. These features are then compared to a database of known objects in order to find a match. The more features that can be extracted from an image, the easier it is to identify the object.
This technology has a wide range of applications, from autonomous vehicle navigation to facial recognition. It can also be used in medical imaging, video production, and surveillance. It has even been used to create interactive apps such as Google Lens and Apple Photos.
There are several technologies used in image recognition, including artificial neural networks (ANN), convolutional neural networks (CNN), and deep learning. ANN and CNN are used to create models that can recognize specific objects. Deep learning has greater accuracy and is capable of recognizing much more complex objects.
In order for any type of machine learning system to work, it needs to be trained first. This requires labeled data sets that provide the machine with examples of what a particular object looks like. As the system is exposed to more examples, it can start recognizing new objects without further human input.
Image recognition has come a long way since its inception and will continue to improve as more data is collected and algorithms become more sophisticated. Although there are still issues to be addressed such as privacy concerns, the technology is quickly becoming a powerful tool for a wide range of tasks.
Robotics and machine learning have become two of the most prominent technology trends of the last decade. Robotics and machine learning are both fields of study that involve the use of data to create autonomous devices and machines that can interact with their environment and make decisions without requiring direct input from a human operator.
Robotics is the science of designing, constructing, and operating machines with the goal of augmenting human capabilities. This includes robots that are capable of sensing, reasoning, and taking action in a human-like way. By automating tasks that would otherwise require manual labor, robots increase productivity, reduce costs, and free up humans to focus on more complex tasks.
Meanwhile, machine learning is a type of artificial intelligence that uses algorithms and data sets to identify patterns in data and make predictions about future behavior. It can be used to automate repetitive tasks, identify trends, and provide personalized recommendations. It is currently being used in healthcare, retail, financial services, customer service, cybersecurity, and many other industries.
The combination of robotics and machine learning is an especially powerful one. By combining the flexibility of robots with the power of machine learning algorithms, organizations can automate tasks with greater accuracy than ever before. In addition, robots can be programmed to learn through experience, allowing them to continually improve over time. This can give them the ability to navigate unfamiliar or constantly-changing environments without needing direct input from a human operator.
Robots also have the potential to become an integral part of our lives. From assisting in surgery to providing companionship to elderly citizens, there is no limit to how robots can help us in our daily lives. As the technology continues to improve, we can look forward to robots becoming even more embedded into our everyday lives.
All in all, robotics and machine learning are two powerful technologies that have the capability to revolutionize the way we think about automation. By combining the strengths of these two technologies, businesses can streamline processes and create experiences that were previously unattainable. It will be exciting to see how this marriage of technologies continues to evolve in the future.
Autonomous vehicles have been on the cutting edge of technology for quite some time now. They are an example of artificial intelligence, or AI, and involve machines learning from their environment and acting without human intervention. Autonomous vehicles use machines to collect data from their environment and make changes accordingly. The data collected from these vehicles can help them reach destinations faster, follow paths better, and detect obstacles sooner than humans can.
Autonomous vehicles typically take in several types of data from their environment. This data includes information about the roads, other vehicles, and pedestrian traffic. The sensors within the car are able to identify patterns and movement in their environment and respond accordingly. Autonomous vehicles also have algorithms built in that allow them to recognize objects and react to them accordingly.
Another important aspect of autonomous vehicles is their machine learning capabilities. Machine learning algorithms enable autonomous vehicles to “learn” from the data they collect from the environment. As autonomous vehicles analyze their environment over time, their algorithms become more accurate and efficient. This means that autonomous vehicles can reach their destination faster and more accurately than a human driver.
One way in which machine learning has been used in autonomous vehicles is in self-driving cars. Self-driving cars are able to recognize obstacles and respond to them accordingly by changing lanes or slowing down. They are also able to detect dangers such as potholes and adjust their route to avoid them. Additionally, self-driving cars are able to map out efficient routes and avoid traffic jams by analyzing data they collect from their environment.
In addition to self-driving cars, machine learning is being used in many other types of autonomous vehicles, such as buses, drones, delivery robots, and unmanned aerial vehicles. All of these autonomous vehicles are able to sense their environment and make decisions based on the data they collect. By using machine learning algorithms, autonomous vehicles can become more reliable, efficient, and safer than ever before.
The use of machine learning algorithms in autonomous vehicles is revolutionizing the way we travel, work, and live. Autonomous vehicles are able to sense their environment faster than humans can and respond accordingly. This allows for safe navigation, efficient routes, and better decision making. As autonomous vehicle technology improves, we will see more machines being able to autonomously navigate around our environment without the need for human intervention.

Machine learning is a powerful tool for improving the speed and accuracy of a variety of processes. By leveraging the power of machine learning, businesses and individuals can create interesting, useful, and cost-effective applications for tasks that previously required time-consuming manual labor or complex programming. From automating the process of analyzing large datasets to predicting user behavior, the potential for machine learning to make workflows more efficient is vast.
Although machine learning can be daunting for those unfamiliar with its inner workings, its benefits are too great to ignore. By taking advantage of available resources such as tutorials, online forums, and blogs, users can quickly get up to speed on how to implement and use machine learning in their projects. With access to these resources and an understanding of the fundamentals of machine learning, users can start taking advantage of the power it offers and unlock the efficiency gains it brings.
In conclusion, machine learning is an incredibly powerful tool that can help businesses and individuals save time and money while unlocking insights and opportunities they could not have had before. With the right resources and understanding of the basics, users can leverage machine learning to streamline their workflows and create meaningful applications.
The introduction of automated machine learning (AutoML) has revolutionized the way data scientists can develop, implement and optimize models for data-driven tasks. As more users have adopted AutoML, it has become clear that this technology is a powerful tool for businesses seeking to maximize their machine learning capabilities. Automated learning helps organizations quickly identify the right data and automates the entire modeling process, saving time and money while creating better models.
In essence, AutoML takes the manual work out of developing effective ML models. It uses algorithms designed to explore a large set of different models with different hyperparameters, which allows it to determine the most accurate model with the least amount of effort. This eliminates the need for manual tuning and allows data scientists to focus on building better features and processes to improve models.
AutoML can be used for a wide range of tasks, from image recognition and natural language processing to predictive analytics and more. The technology can even be used to create neural networks that can automate complex tasks such as facial recognition and autonomous driving. Its applications are only growing as businesses continue to realize the benefits that come from its use.
One of the key advantages that AutoML offers is faster model development timelines. With traditional ML procedures, data scientists would typically spend weeks or months trying to manually tune their models for optimal performance. With AutoML, data scientists can quickly find the most accurate and effective model within minutes, allowing them to focus more time on other tasks such as feature engineering or performance optimization.
The ability to quickly create high-quality models also makes AutoML an attractive solution for businesses seeking rapid innovation. This technology is designed to quickly find accurate models that can be used in production environments, making it easier for companies to rapidly deploy new products or services.
Finally, it is important to recognize that AutoML also enables organizations to scale their ML operations by taking advantage of off-the-shelf hardware. This means that businesses can begin building and testing models at scale without having to acquire expensive server hardware or hire additional personnel.
Overall, AutoML has become an essential part of the modern data science pipeline due to its ability to dramatically reduce development time, enhance production capabilities and simplify the process of scaling ML operations. For businesses looking to maximize their machine learning capabilities, it is an invaluable asset that should not be overlooked.
In the business world, there is a lot of talk about the power of automation. In fact, there is a lot of talk about the power of automation across all aspects of life. Automation is seen as a way to make our lives easier and more efficient. And, when it comes to business, automation can be a powerful tool for growth. But what is automation, and how can it help your business?
Automation is the use of technology to control or manage a process. In business, this can mean using technology to automate tasks that are traditionally done by people. For example, you can use automation to automatically generate invoices, send out emails, or track inventory.
Automation can help your business in a number of ways. First, it can help you save time and money. Automation can automate tasks that are time consuming and expensive to do manually. For example, you can use automation to automate the process of ordering inventory, which can save you time and money.
Second, automation can help you improve your efficiency. Automated systems are often more efficient than manual systems. For example, you can use automation to automatically generate invoices. This can help you improve your billing process and reduce the amount of time it takes to generate invoices.
Third, automation can help you improve your accuracy. Automated systems are often more accurate than manual systems. For example, you can use automation to automatically track inventory. This can help you reduce the amount of inventory that is lost or misplaced.
Fourth, automation can help you improve your customer service. Automated systems can help you respond to customer inquiries more quickly and efficiently. For example, you can use automation to automatically send out email notifications when a product is back in stock. This can help you reduce the amount of time it takes to respond to customer inquiries.
Finally, automation can help you improve your competitiveness. Automated systems can help you reduce your operating costs and improve your efficiency. This can help you compete more effectively in the market.
So, how can you start using automation in your business? Here are a few tips:
1. Identify tasks that can be automated.
2. Evaluate the benefits of automation.
3. Choose the right automation tool for the job.
4. Implement the automation tool.
5. Evaluate the results.
6. Make changes as needed.
The potential of artificial intelligence (AI) for machine learning is virtually limitless. While it may not be able to replace humans completely, AI has already begun to revolutionize entire industries, from finance to health care. AI is a powerful technology that is quickly becoming the new normal, used across a range of applications to improve productivity and efficiency in both the public and private sectors.
AI has already had a significant impact in machine learning, with algorithms being developed to process vast amounts of data in order to make more informed decisions. For example, AI is being used in retail to accurately predict customer buying patterns and preferences. AI can also help reduce costs by automatically detecting and responding to customer inquiries and needs. Machine learning also has potential applications in healthcare, where AI can be used to analyze vast amounts of medical data and detect diseases early on. AI can be used to streamline processes and make organizations more efficient.
The potential of AI for machine learning is growing each day as we uncover new ways of applying the technology. For example, natural language processing (NLP) is one area that has seen tremendous growth recently. Natural language processing allows computers to understand and respond to human speech in real time, which makes it possible to create automated chatbots and interactive experiences with customers. NLP is also being used in areas such as medical diagnosis and fraud detection.
As technology advances and more possibilities become available through AI, the potential of machine learning will only continue to grow. AI is a powerful tool that can be used in any industry to make decisions more accurately, quickly and efficiently. The possibilities of AI for machine learning are truly limitless.

In recent years, there has been a great deal of discussion surrounding the potential for artificial intelligence (AI) to revolutionize the world as we know it. While there is no doubt that AI has the ability to transform entire sectors and industries, there is still some uncertainty as to what this future will look like.
One of the key benefits of AI is its ability to automate tasks that would traditionally require human input. In many cases, this can result in increased efficiency and accuracy, as well as reduced costs. For example, AI can be used to automatically process and analyze large amounts of data, which can improve decision-making processes.
AI can also be used to improve customer service. For example, chatbots can be used to automatically respond to customer inquiries, which can free up customer service representatives to deal with more complex issues. AI can also be used to personalize customer experiences, which can lead to increased customer loyalty.
AI has the potential to revolutionize a wide range of industries, including healthcare, finance, transportation, and manufacturing. However, it is important to note that there are also a number of potential risks associated with AI. For example, there is a risk that AI could be used to automate jobs, which could lead to unemployment. There is also a risk that AI could be used to manipulate data, which could lead to inaccurate decision-making.
Despite these risks, the potential benefits of AI are too great to ignore. With the right guidance and oversight, AI can be used to improve efficiency, accuracy, and customer service across a wide range of industries.
Exploring the Boundaries of Machine Intelligence for Machine Learning has become a major focus of the tech industry in recent years. Machine learning is an approach to Artificial Intelligence that uses algorithms to learn from data and make predictions or decisions. It involves the use of data-driven models that can identify patterns and make decisions.
As machine learning continues to advance, the boundaries of machine intelligence are being pushed. Machine learning can now be used to solve complex problems that were once beyond our capabilities. One example is using machine learning to detect fraud in financial transactions. This technology can be used to identify suspicious activity and alert system administrators so they can take the appropriate steps to prevent fraud.
In addition, machine learning can be used for more mundane tasks, such as data analysis for business intelligence and marketing campaigns. For example, machine learning can be used to predict customer buying behavior, allowing businesses to target their marketing efforts in a more effective and efficient way.
The possibilities of machine learning are limitless, and the boundaries of machine intelligence are constantly being explored by researchers. As the technology advances, it can be used in a variety of ways, from self-driving cars to more complex tasks like predicting the stock market. The potential of machine learning is still being discovered and explored, with new applications being found every day.
As machine learning continues to evolve, so do the implications for its use in society. There are ethical considerations when using machine learning for decision-making, as well as potential legal implications. Proper safeguards must be put in place when using machine learning for decision-making, as it could open up the door for potential abuse or misuse of data.
Ultimately, the exploration of the boundaries of machine intelligence is a necessary part of advancing the technology. New applications are being found every day, and this research will help maintain ethical standards while also enabling us to take advantage of all the potential benefits that machine learning has to offer.

Machine intelligence has come a long way in recent years. With the advent of big data and the ever-growing power of computers, machines are now able to learn and make decisions on their own. But where does machine intelligence end and human intelligence begin? And where do the boundaries of machine intelligence lie?
One of the biggest challenges for machine intelligence is understanding natural language. Computers are good at understanding symbols and numbers, but they struggle with understanding the complexities of human language. In order to truly understand human intelligence, we need to find a way for machines to understand the nuances of human communication.
Another challenge for machine intelligence is dealing with uncertainty. Machines are good at dealing with certainty, but they struggle with dealing with uncertainty. In order to deal with uncertainty, we need to find a way for machines to be able to make decisions in the face of uncertainty.
One of the boundaries of machine intelligence is the ability to reason and think abstractly. Machines are good at dealing with concrete facts, but they struggle with dealing with abstract concepts. In order to reason and think abstractly, we need to find a way for machines to be able to understand the relationships between objects.
Another boundary of machine intelligence is the ability to create and innovate. Machines are good at following rules, but they struggle with coming up with new ideas. In order to create and innovate, we need to find a way for machines to be able to come up with new ideas on their own.
So where do the boundaries of machine intelligence lie? And where does human intelligence begin? These are questions that we are still trying to answer. But as machine intelligence continues to evolve, we will get closer and closer to understanding the boundaries of machine intelligence and human intelligence.
Data-driven solutions for machine learning have enabled businesses to make more accurate and informed decisions in order to remain competitive in their respective industries. By leveraging the power of data-driven solutions, businesses can gain extensive insights from their data, develop better models, and gain a more comprehensive understanding of their customers.
In the past, businesses had to rely on manual processes and labor-intensive approaches to gain insight from their data. However, with advances in big data and artificial intelligence, data-driven solutions for machine learning have made it easier to gain insights quickly and accurately. For example, machine learning algorithms can help to identify patterns in large volumes of data that were previously difficult to detect. This type of analysis allows businesses to better understand customer behavior, trends, and preferences in order to make more informed decisions.
In addition to being able to better analyze customer data, businesses can also use data-driven solutions for machine learning to develop better models. Machine learning algorithms can identify important features in data that can be used to create more accurate predictive models. This allows businesses to develop models that are more reliable and can provide better insights into customer needs and preferences.
Finally, businesses can also take advantage of data-driven solutions for machine learning by leveraging automated decision support systems. These systems use artificial intelligence algorithms to provide recommendations for various business decisions such as marketing campaigns or product launches. Automated decision support systems can save businesses time and money by eliminating manual processes and improving the accuracy of recommendations. In addition, automated decision support systems can provide valuable insights into customer preferences that can be used to make more effective decisions.
In conclusion, businesses can benefit greatly from data-driven solutions for machine learning. By leveraging the power of big data and AI algorithms, businesses can gain better insights into customer behavior, develop more accurate models, and utilize automated decision support systems in order to remain competitive in their respective industries.
The world of business is constantly evolving, and with this evolution comes new and innovative ways of doing things. In order to stay ahead of the competition, businesses must be willing to change and adapt to the ever-changing landscape. One of the most important aspects of doing business in the 21st century is harnessing the benefits of data-driven solutions.
What are data-driven solutions?
Data-driven solutions are business processes that are driven by data. In other words, data is the key factor in making decisions and taking actions. This can include anything from data analysis to data-driven marketing.
Why are data-driven solutions important?
Data-driven solutions are important because they allow businesses to make better decisions, faster. By analyzing data, businesses can identify trends and patterns that would otherwise be invisible. This information can then be used to make informed decisions about everything from product development to marketing strategy.
How can businesses get started with data-driven solutions?
There are a number of ways businesses can get started with data-driven solutions. One of the most important things is to identify the areas of the business that could benefit from data analysis. Once these areas have been identified, businesses can start collecting and analyzing data to see what trends and patterns emerge.
It’s also important to have a solid data management plan in place. This plan should include a strategy for collecting data, storing data, and analyzing data. And finally, businesses need to have the right tools and technology in place to support data-driven solutions.
The benefits of data-driven solutions are clear. By using data to make decisions, businesses can improve their bottom line and stay ahead of the competition.
In recent years, machine learning has become an invaluable tool in automating decision-making processes. Automated decision-making makes it possible to quickly and accurately process large amounts of complex information and execute decisions based on predetermined criteria, saving businesses time and money. Although automated decision-making can be extremely effective, the technology continues to evolve and its inner workings remain something of a mystery to those outside the field. In this article, we’ll explore the mysteries of automated decision-making for machine learning in order to gain a better understanding of this exciting technology.
The first step in unlocking the mysteries of automated decision-making is to understand supervised and unsupervised learning. Supervised learning is the process by which data is labeled and classified according to certain criteria. This data can then be used by models to make decisions based on the predetermined criteria. Unsupervised learning, on the other hand, involves collecting data without labeling it, then using algorithms to discover patterns in the data. This process allows machines to recognize trends and make decisions without direct human input.
Once these two concepts are understood, it’s important to understand how machine learning models work. Models are essentially algorithms that are designed to interpret inputs and generate output decisions based on those inputs. They use a combination of supervised and unsupervised learning techniques in order to make the best possible decisions. The models weigh different factors, such as accuracy, precision, recall and cost in order to evaluate input variables and determine the most appropriate output decision.
Finally, it’s essential to understand the role that artificial intelligence and deep learning play in automation. AI and deep learning allow machines to perform highly sophisticated tasks such as image recognition, natural language processing, and speech recognition. Deep learning algorithms provide machines with a way of understanding complex data more efficiently, while AI allows them to take independent action when faced with complex problems.
Automated decision-making is an incredibly powerful tool that can save businesses time and money. Although the technology is still evolving, by understanding these key concepts it’s possible to unlock the mysteries of automated decision-making for machine learning and take advantage of this powerful technology.

In the business world, there is an increasing demand for automated decision-making (ADM). This is the process of using technology to make decisions for us, instead of relying on humans. ADM offers a number of advantages, including increased efficiency and accuracy, and the ability to scale.
However, there is still a lot of mystery surrounding ADM. In particular, there is a lot of confusion about what ADM is and how it works. In this article, we will dispel some of the myths about ADM, and provide a clear and concise explanation of what it is and how it works.
First, let’s start with a definition. Automated decision-making is the process of using technology to make decisions for us, instead of relying on humans. ADM can be used to make decisions in a wide range of areas, including finance, marketing, operations, and human resources.
ADM is made possible by a technology called artificial intelligence (AI). AI is a branch of computer science that deals with the design and development of intelligent computer systems. These systems are capable of performing tasks that normally require human intelligence, such as understanding natural language, recognizing objects, and making decisions.
AI is used to create the algorithms that power ADM. These algorithms are used to analyze data and identify patterns. Once the patterns have been identified, the algorithm will make a decision based on the patterns it has identified.
ADM can be used to make decisions in a wide range of areas, including finance, marketing, operations, and human resources.
There are a number of advantages to using ADM. First, ADM is more efficient than human decision-making. Humans are limited by their ability to process information and make judgments. ADM is not limited by these factors, and can make decisions faster and more accurately than a human can.
Second, ADM is scalable. This means that it can be used to make decisions in large organizations, where there is a lot of data to be analyzed. ADM can also be used to make decisions in real time, which is not possible with human decision-makers.
Third, ADM is more accurate than human decision-making. Humans are prone to making mistakes, due to their limited knowledge and judgment. ADM is not limited by these factors, and can make decisions more accurately than a human can.
Fourth, ADM is unbiased. Human decision-
With the advancements of artificial intelligence, machine learning and predictive analytics, a novel form of predictive analysis has emerged – automated predictive analytics. This technology is taking data science to the next level by bringing together state-of-the-art machine learning algorithms and decision models to provide more accurate and reliable business decisions. Automated predictive analytics applies powerful machine learning models to extensive sets of data and then use the results to offer timely and accurate predictions about future events and decisions.
The potential of automated predictive analytics for businesses and organizations is vast. It can be used to analyze a wide range of data sources, from customer feedback surveys to website analytics, to identify patterns and trends in customer behavior. This allows companies to gain deeper insight into their customers’ needs and demands, enabling them to create strategies that are tailored to their audience. Companies can also use automated predictive analytics to assist in the development of product features and pricing models. By applying sophisticated machine learning techniques, organizations can discover correlations between different product features, giving businesses a better understanding of which features are most beneficial or used by customers.
In addition to its uses in product development, automated predictive analytics can also be applied to marketing campaigns. By analyzing consumer profiles and clickstream data, automated predictive models can identify which customers will respond favorably to specific marketing techniques. This insight can then be used to tailor the campaigns for more successful outcomes.
Automated predictive analytics can also be used for predicting market trends and predicting consumer purchasing behavior. By applying advanced algorithms to large sets of data, automated predictive analytics can accurately predict consumer purchase patterns and market trends. This in turn can help companies better prepare their marketing campaigns to reach their target audience more effectively.
Overall, automated predictive analytics is proving itself as a revolutionary tool for businesses and organizations. With its help, companies can more accurately predict future events, gain deeper insights into customer behavior, and develop marketing strategies that are tailored for success. The potential for automated predictive analytics is only just beginning to be realized and its potential will continue to grow as its capabilities evolve.

Most people think of predictive analytics as a tool to help them make better decisions. Automated predictive analytics is a tool that can do that for you. It uses algorithms to analyze data and identify patterns. It can then use those patterns to predict future events. Automated predictive analytics is a great tool for businesses because it can help them make better decisions about pricing, product development, and marketing.
There are a number of different types of automated predictive analytics tools. Each tool uses a different algorithm to analyze data. The most common types of automated predictive analytics tools are decision trees, support vector machines, and artificial neural networks.
Decision trees are a type of automated predictive analytics tool that uses a hierarchical structure to analyze data. It starts by identifying the most important factors in a problem. It then uses those factors to identify the best course of action. Decision trees are used to make decisions about things like credit risk and product pricing.
Support vector machines are a type of automated predictive analytics tool that uses a mathematical algorithm to analyze data. It identifies the important features in a data set and then uses them to create a model that can predict future events. Support vector machines are used to make decisions about things like credit risk and product pricing.
Artificial neural networks are a type of automated predictive analytics tool that uses a simulated brain to analyze data. It identifies the important features in a data set and then uses them to create a model that can predict future events. Artificial neural networks are used to make decisions about things like credit risk and product pricing.
Each of these types of automated predictive analytics tools has its own strengths and weaknesses. You should choose the tool that best suits your needs.
Innovations in the world of technology are driven by the advances in machine learning. Machine learning is a branch of artificial intelligence (AI) which focuses on the development of computer programs that can access data, identify patterns and make decisions with minimal human intervention. By leveraging the power of AI, enterprises can gain a competitive edge in the marketplace.
The purpose of machine learning is to enable autonomous systems and robots to not only understand and interact with their environment, but also to efficiently process vast amounts of data in order to perform optimally. For example, through predictive analytics, businesses can benefit from machine learning-driven insight into customer behaviors and preferences. This helps them to better tailor strategies and services to meet their needs.
Another application of machine learning is autonomous vehicles where computer-controlled vehicles are able to navigate roadways without any human input. This technology is being applied in many areas such as on-demand ridesharing services, delivery services, public transportation, and autonomous trucks. The cars use sensors and other technologies such as GPS and cameras to detect obstacles and take evasive action as necessary.
Through natural language processing (NLP), machines are able to understand and interpret human speech, leading to more intelligent decision making. For example, virtual assistants such as Amazon Alexa and Google Assistant can respond to voice commands and provide insights based on user queries. NLP also plays a big role in deep learning applications for image and object recognition.
In the medical field, machine learning is being used to diagnose diseases with more accuracy than ever before. In addition, AI-driven algorithms are increasingly being used for drug discovery and development. They are able to analyze large data sets of medical records and genomic data to find correlations between patient characteristics and drug responses.
Overall, machine learning is showing tremendous potential across many different industries. With its ever-increasing capabilities combined with advancements in hardware and software, it has given us an unprecedented level of insight into our world. From autonomous cars to virtual assistants, machine learning is driving the next wave of innovation that will shape our future.

Machine learning is a process of teaching computers to learn from data without being explicitly programmed. It has revolutionized the process of data analysis and has led to the development of powerful algorithms that can automatically learn and improve from experience.
Machine learning is widely used in a variety of domains such as finance, healthcare, retail, manufacturing, and logistics. In the automotive industry, machine learning is used to improve the safety and efficiency of vehicles. Some of the applications of machine learning in the automotive industry are as follows:
1. Driverless cars: Driverless cars use machine learning algorithms to detect and avoid obstacles on the road.
2. Traffic management: Machine learning is used to optimize traffic flow and reduce congestion.
3. Vehicle maintenance: Machine learning is used to predict vehicle failures and schedule maintenance accordingly.
4. Car-sharing: Machine learning is used to match drivers and passengers for car-sharing.
5. Autonomous driving: Machine learning is used to control the steering, braking, and throttle of a vehicle in autonomous driving.
Machine learning has the potential to revolutionize the automotive industry. It can help automakers to develop safer and more efficient vehicles. It can also help them to reduce costs and improve customer satisfaction.
Machine learning has been a rapidly growing field over the last decade, and it’s no surprise that one of the key areas of focus for researchers and developers is the art of automated problem-solving. Automated problem-solving allows for machines to think and react on their own, without having to be manually programmed. As machine learning technologies become increasingly powerful and efficient, mastering the art of automated problem-solving will be essential for the advancement of this field.
One key aspect of automated problem-solving is predictive analytics. Predictive analytics involves using data collected by a machine to predict future outcomes or trends. This technology can be used in various fields such as finance, healthcare, and cybersecurity, to better anticipate and manage potential risks. Artificial neural networks are a type of predictive technology that can be used to create models that accurately understand and learn from data. By leveraging neural networks, complex patterns and insights can be derived from large datasets, which can then be used to automate decisions or processes that could previously only be done manually.
In addition to predictive analytics, automation can also be used for decision-making. Automated decision-making uses algorithms and techniques such as reinforcement learning and genetic algorithms to help machines make decisions based on certain criteria or objectives. With this technology, machines can autonomously explore the environment and learn on their own in order to reach the desired goal. This type of automation has been particularly useful in robotics, where complex tasks can be assigned and completed without manual intervention.
An important element of automated problem-solving is natural language processing (NLP). NLP is a type of machine learning technology that focuses on understanding how humans interact with machines and vice versa. This technology gives machines the ability to comprehend human language and respond accordingly. NLP can be used in a variety of applications such as chatbots, automated customer service systems, and voice-activated digital assistants.
Finally, mastering automated problem-solving also involves developing robust machine learning pipelines. A machine learning pipeline is composed of several components working together in order to achieve a certain goal. These components may include data preprocessing, feature engineering, model building/training/evaluation, automated model selection, deployment of models into production environments, and more. By understanding how these components work together, developers can create powerful machine learning pipelines that can effectively solve complex problems in an automated fashion.
In conclusion, mastering the art of automated problem-solving is essential for the success of machine learning technologies. Automated problem-solving enables machines to think and act on their own by leveraging technologies such as predictive analytics, automated decision-making, natural language processing, and machine learning pipelines. By understanding these technologies and building robust machine learning pipelines, developers can create powerful solutions to difficult problems in an automated fashion.
Computers are amazing tools that can help us solve problems in ways we never could before. However, programming computers to solve problems can be difficult and time-consuming. In this article, we will explore some techniques for automating the process of problem-solving using computers.
One of the most important things to understand when automating problem-solving is the concept of a “ algorithm”. An algorithm is a set of instructions that can be followed to solve a problem. When programming a computer to solve a problem, we often need to create an algorithm that tells the computer how to solve the problem.
There are a variety of different techniques that can be used to create algorithms. One technique that is often used is called “ recursion”. Recursion is a technique that involves breaking a problem down into smaller and smaller pieces until the problem can be solved. This technique can be used when creating algorithms for problems that can be solved using a “ divide and conquer” strategy.
Another technique that can be used when creating algorithms is called “ dynamic programming”. Dynamic programming is a technique that can be used to solve problems that can be broken down into a series of smaller problems. This technique is often used when solving problems that involve a “ greedy” strategy.
Once we have created an algorithm that solves a problem, we need to program the computer to use the algorithm. This can be done using a variety of programming languages, such as Python, C++, or Java.
Once the computer is programmed to use the algorithm, we can test the algorithm by solving a problem. If the algorithm works correctly, the computer should be able to solve the problem faster and more accurately than a human can.
By understanding the concepts of algorithms and programming, we can create computers that can solve problems for us faster and more accurately than we ever could before.
The recent advancements in technology have made automation an integral part of our lives. It has made mundane tasks easier and faster. Automation also plays a major role in machine learning by helping to process bigger data sets quickly, thus enabling us to gain better insights from them.
Automation is the use of machines or software to perform a task without human intervention. It is the process of making tasks easier and faster by automating a certain process. This saves time and energy, as well as reduces errors in the process.
When it comes to machine learning, automation can be used for a variety of tasks such as data pre-processing, training, testing, and deployment. Automation helps make machine learning models more efficient by simplifying the data pre-processing stage. This includes cleaning data, selecting appropriate features, normalizing them, and so on. Automation also helps in training and testing machine learning models by streamlining the whole process. This includes setting parameters, tuning models, and validating results. Moreover, automation can help with the deployment of machine learning models by automating the entire process of model creation and deployment.
The advantages of automation for machine learning are clear – it increases efficiency, reduces errors, and speeds up the process. This can lead to more accurate predictions and improved accuracy of machine learning models.
Moreover, automation can also be used for other tasks such as building datasets from scratch, refining existing datasets, creating pipelines for data ingestion and feature engineering, as well as monitoring system performance. This helps optimize the data pipeline and make sure that data is processed efficiently.
In conclusion, automation is an integral part of machine learning as it makes it easier to process large amounts of data quickly and accurately. Automation can be used for a variety of tasks such as data pre-processing, training, testing, deployment and monitoring system performance. This can lead to improved accuracy of machine learning models and better predictions. Therefore, unleashing the possibilities of automation can open up new opportunities in machine learning.

There is no doubt that automation has had a profound impact on the workplace. From reducing the need for manual labor to automating routine tasks, automation has made workers more productive and efficient. But what many people don’t realize is that automation can also unleash the possibilities of creativity and innovation.
For example, consider the way that automation has changed the way we design products. With the help of 3D printers and computer-aided design (CAD) software, designers can now create products that are not only more efficient, but also more stylish and visually appealing. In the past, designers were limited by the amount of time and manpower they had available. But with the help of automation, they can now create products that are not only faster and easier to produce, but also more complex and sophisticated.
Automation has also had a profound impact on the way we do business. With the help of automation, businesses can now manage their operations more effectively and efficiently. Automation can help businesses to streamline their processes, improve communication, and reduce costs.
Automation has also had a profound impact on the way we live our lives. With the help of automation, we can now manage our time more effectively and get more done in less time. Automation can help us to manage our finances more effectively, stay connected with friends and family, and find information quickly and easily.
So, what does the future hold for automation?
The future of automation is bright. With the help of automation, we can now do things that were once impossible. We can now manage our lives more effectively and efficiently, and we can now unleash the possibilities of creativity and innovation.
The concept of machine learning has been around for decades, but it is only recently that businesses have begun to recognize the potential of this technology to revolutionize their operations. Machine learning has enabled computers to learn from experience and data in order to make better decisions, improve processes and create more efficient systems. Its potential to revolutionize business is vast, and many companies are already leveraging its capabilities.
Businesses of all sizes are beginning to implement machine learning into their operations in order to drive down costs, reduce errors, and increase efficiency. By feeding algorithms large amounts of data about customer behaviour, trends in the market, and other factors, machine learning can help companies to make informed decisions quickly and accurately. This allows them to respond to changes in the market faster and more effectively than ever before.
Machine learning can also be used to automate certain processes, freeing up employees time for tasks that require more human skills. For example, many businesses have been using machine learning to automate customer service inquiries or analyze customer behaviour in order to provide a better service. Machine learning can also be used for fraud detection, allowing companies to act quickly when unauthorized activity is detected. This technology can also enable businesses to better target advertising campaigns, by analyzing past customer behaviour and predicting future customer preferences.
In addition to these practical applications, machine learning can also help businesses to innovate faster than ever before. By utilizing algorithms that can rapidly spot trends in customer behaviour and market movements, companies can move faster to capitalize on new opportunities, while reducing the amount of time and money they spend on research and development.
The potential of machine learning is vast, and the possibilities it offers businesses are seemingly endless. From automation to innovation, machine learning has the power to revolutionize businesses of all sizes and industries. As this technology continues to evolve, businesses must stay ahead of the curve in order to remain competitive and successful in an increasingly digital world.

Machine learning is a process of programming computers to make decisions without being explicitly programmed. It is a subset of artificial intelligence that enables computers to learn from data, identify patterns and make predictions.
Machine learning has many potential applications in business. It can be used to improve decision-making, increase productivity and efficiency, and create a competitive advantage.
Some of the ways machine learning can be used in business include:
1. Improving decision-making
Machine learning can be used to improve decision-making by helping businesses to better understand their customers and make more accurate predictions.
2. Increasing productivity and efficiency
Machine learning can be used to automate tasks and improve processes, which can lead to increased productivity and efficiency.
3. Creating a competitive advantage
Machine learning can be used to give businesses a competitive advantage by helping them to better understand their customers, competitors and industry.

I. Introduction NEOM is a $500 billion, 26,500 square ...

Over the last two decades the internet has evolved from...

Mostly many of candidates confused or do not have idea ...
You cannot copy content of this page


